Facebook was inaccessible (and down) for many hours, affecting all users and many businesses. As their DNS was not responding, several DNS providers and ISPs suffered from large traffic increases and some had outages as a consequence. Some sites using FB javascript were reported as loading slowly (because the JS would not be found but needed to time out.)
Cloudflare blogged:
No useful details from Facebook’s engineering blog:
Animations of the routes to the vital netblock being torn down within:
Facebook Down and Out in BGPlay
Then over the next ten minutes or so, we see lots of activity until finally, at 15:53:47 (UTC), all the links are gone. At that time, the Internet no longer had any routes to the prefix 129.134.30.0/24, a prefix containing an important piece of the Facebook network (more specifically, the authoritative DNS name server - a.ns.facebook.com - for the facebook.com domain).
An insider posted some notes on Reddit, before deleting them, and then deleting their account: here’s a capture:
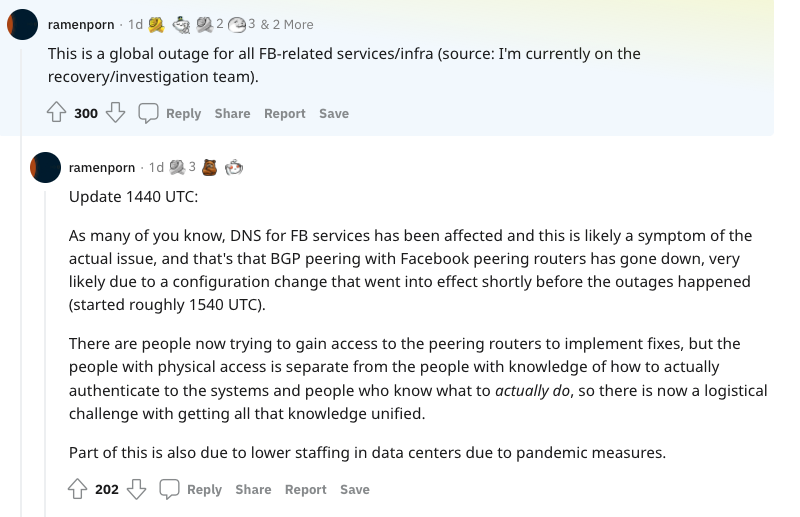
No discussion that I’m aware of yet that is considering a threat/attack vector. I believe the original change was ‘automatic’ (as in configuration done via a web interface). However, now that connection to the outside world is down, remote access to those tools don’t exist anymore, so the emergency procedure is to gain physical access to the peering routers and do all the configuration locally.
Update 1440 UTC: As many of you know, DNS for FB services has been affected and this is likely a symptom of the actual issue, and that’s that BGP peering with Facebook peering routers has gone down, very likely due to a configuration change that went into effect shortly before the outages happened (started roughly 1540 UTC). There are people now trying to gain access to the peering routers to implement fixes, but the people with physical access is separate from the people with knowledge of how to actually authenticate to the systems and people who know what to actually do, so there is now a logistical thing with getting all that knowledge unified.
See also the HN discussion.